一、背景
RocketMQ无论采用Master/Slave的主从模式,还是采用Dledger的多副本模式,均能保证RocketMQ集群的高可用性,但在一些极端场景下,例如机房断电、机房火灾、地震等不可抗拒因素使得该IDC可用区的RocketMQ集群无法正常对外提供消息服务能力。因此,为了增强抗风险能力,消息队列RocketMQ集群多活异地容灾极为重要。
二、物理部署异地容灾方案
 图2-1 物理部署异地容灾方案图
图2-1 物理部署异地容灾方案图
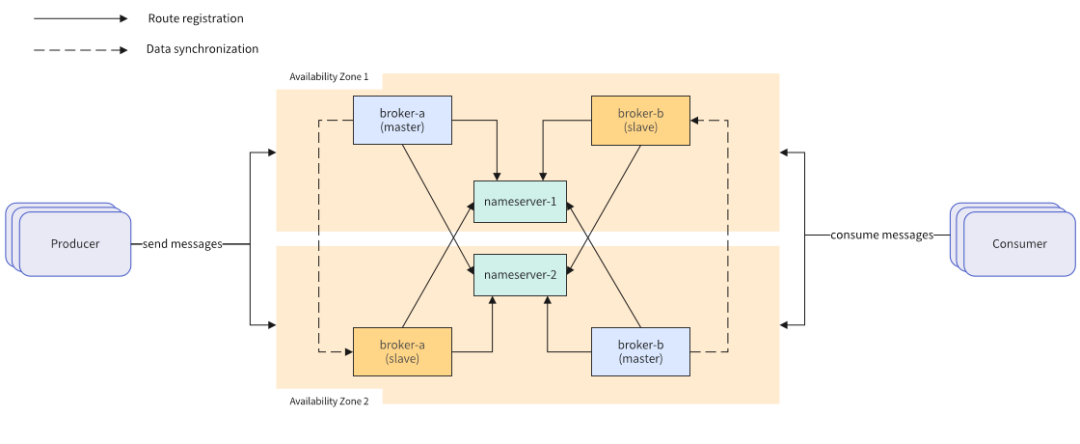
移动云部署的RocketMQ采用的Master/Slave的主从模式,其中物理部署异地容灾的方案包括以下几部分:
(1) NameServer组件作为轻量级注册中心,无状态,负责更新和发现 Broker服务Namesrv之间相互没有通信,单台Namesrv宕机不影响其他Namesrv节点与集群的功能,两台Namesrv部署在不同的可用区,当一个可用区故障,另外一个可用区的Namesrv依然能对外提供服务。
(2) Broker组件作为消息中转角色,负责存储消息,转发消息,采用Master/Slave部署模式,在两个可用区上交叉部署(如broker-a的Master部署在可用区1上,Slave节点部署在可用区2上,broker-b的Master部署在可用区2上,Slave节点部署在可用区1上),消息发送到Master节点后会实时同步到Slave节点,保证每个可用区保存了全量的消息。当单个可用区故障也会对外提供消息的读写能力。
三、云化版本异地容灾单集群方案
针对物理机部署RocketMQ运维、迁移、扩缩容费时费力,操作复杂;业务增加以后,资源无法弹性,手动扩缩容实时性差;底层资源利用率不高,用户资源隔离和流量的管控需要额外投入等问题。可以借助K8S Operator,Operator 的工作原理,实际上是利用了 Kubernetes 的自定义 API 资源(如使用CRD,CustomResourceDefinition),来描述想要部署的应用;然后在自定义控制器里,根据自定义 API 对象的变化,来完成具体的部署和运维工作,实现Operator主要关键是 CRD(自定义资源)和 Controller(控制器)的设计。
 图3-1 Operator原理图
图3-1 Operator原理图
自研了RocketMQ Operator实现集群的秒级部署,扩缩容,规格变更等一些列常见的运维操作,进而解决在物理部署所带来的难题。下图是RocketMQ Operator设计实现:
 图3-2 RocketMQ Operator架构图
图3-2 RocketMQ Operator架构图
该方案使用三个异地可用区部署一个K8S集群,每个可用区部署一个master节点,图中的Broker是两主两从高可用方案,采用交叉部署,namesrv每个可用区部署一个实例。
 图3-3 云化异地容灾单集群方案
图3-3 云化异地容灾单集群方案
这个方案存在几个问题:大规模单K8S集群出现故障时可能会对整个集群产生影响,且组件升级难、风险大;随着业务增加,核心组件压力增大,性能下降;单一集群的建设可能受限于特定的地理位置和前期规划,缺乏灵活性。
四、云化版本异地容灾集群联邦方案
针对上述方案的缺点,消息队列RocketMQ云化版本多可用区的现阶段优化为如下方案:
 图4-1 云化异地容灾多联邦集群方案
图4-1 云化异地容灾多联邦集群方案
K8S集群采用云原生Kosmos进行多个集群联邦,不在单纯依赖单个K8S集群,RocketMQ服务资源通过Kosmos CluterTree同步联邦集群间的svc,pod等资源 ,联邦集群间的网络由Kosmos ClusterLink打通。
五、Kosmos简介
Kosmos是移动云的分布式云原生联邦集群技术集合,于2023年8月开源,项目地址:https://github.com/kosmos-io/kosmos。Kosmos包含多集群网络工具ClusterLink、跨集群编排工具ClusterTree等:
 图5-1 Kosmos模块和组件
图5-1 Kosmos模块和组件
ClusterLink的作用是打通多个Kubernetes集群之间的网络,在CNI上层实现,用户无需卸载或重启已经安装的CNI插件,且不会对正在运行的pod产生影响。ClusterLink的主要功能如下:
✓ 提供跨集群PodIP、ServiceIP互访能力
✓ 提供P2P、Gateway多种网络模式
✓ 支持全局IP分配
✓ 支持IPv4、IPv6双栈