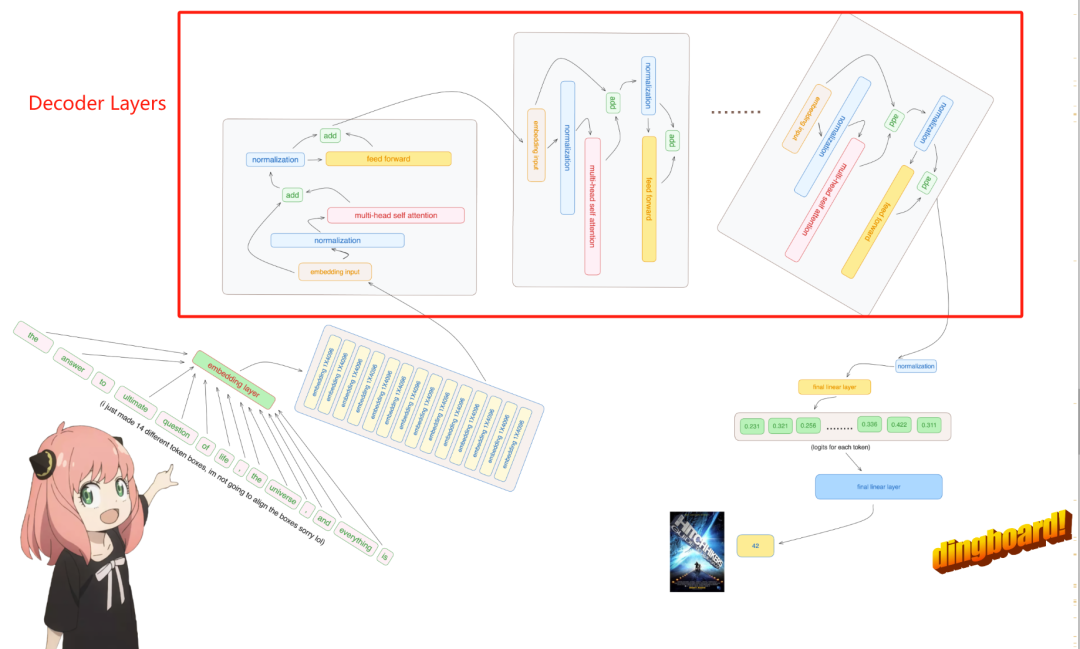
一、Llama3的架构
在本系列文章中,我们从头开始实现llama3。
Llama3的整体架构:
 图片
图片
Llama3的模型参数:
让我们来看看这些参数在LlaMa 3模型中的实际数值。
 图片
图片
[1] 上下文窗口(context-window)
在实例化LlaMa类时,变量max_seq_len定义了context-window。类中还有其他参数,但这个参数与transformer模型的关系最为直接。这里的max_seq_len是8K。
 图片
图片
[2] 词汇量(Vocabulary-size)和注意力层(Attention Layers)
接下来是Transformer类,它定义了词汇量和层数。这里的词汇量是指模型能够识别和处理的单词(和tokens)集。Attention layers指的是模型中使用的transformer block(attention和feed-forward layers的组合)。
 图片
图片
根据这些数字,LlaMa 3的词汇量为128K,这是相当大的。此外,它有32个transformer block。
[3] 特征维度(Feature-dimension)和注意力头(Attention-Heads)
特征维度和attention-heads被引入到Self-Attention模块中。Feature dimension指的是嵌入空间中tokens的向量大小(特征维度是指输入数据或嵌入向量的维度大小),而attention-heads包括驱动transformers中self-attention机制的QK-module。
 图片
图片
[4] 隐藏维度(Hidden Dimensions)
隐藏维度是指在前馈神经网络(Feed Forward)中,隐藏层的维度大小。前馈神经网络通常包含一个或多个隐藏层,这些隐藏层的维度决定了网络的容量和复杂度。在Transformer模型中,前馈神经网络的隐藏层维度通常是特征维度的某个倍数,以增加模型的表示能力。LLama3中,隐藏维度是特征维度的1.3倍。需要注意的是,隐藏层和隐藏维度是两个概念。
更多的隐藏层数量允许网络在将它们投射回较小的输出维度之前,内部创建和操纵更丰富的表示。
 图片
图片
[5] 将上述参数组合成Transformer
第一个矩阵是输入特征矩阵,通过Attention layer处理生成Attention Weighted features。在这幅图像中,输入特征矩阵只有5 x 3的大小,但在真实的Llama 3模型中,它增长到了8K x 4096,这是巨大的。
接下来是Feed-Forward Network中的隐藏层,增长到5325,然后在最后一层回落到4096。
 图片
图片
[6] Transformer block的多层
LlaMa 3结合了上述32个transformer block,输出从一个block传递到下一个block,直到达到最后一个。
 图片
图片
[7] 把所有这些放在一起
一旦我们启动了所有上述部分,就是时候把它们整合在一起,看看它们是如何产生LlaMa效果的。
 图片
图片
步骤1:首先我们有我们的输入矩阵,大小为8K(context-window)x 128K(vocabulary-size)。这个矩阵经过嵌入处理,将这个高维矩阵转换为低维。
步骤2:在这种情况下,这个低维结果变为4096,这是我们之前看到的LlaMa模型中特征的指定维度。
在神经网络中,升维和降维都是常见的操作,它们各自有不同的目的和效果。
升维通常是为了增加模型的容量,使其能够捕捉更复杂的特征和模式。当输入数据被映射到一个更高维度的空间时,不同的特征组合可以被模型更容易地区分。这在处理非线性问题时尤其有用,因为它可以帮助模型学习到更复杂的决策边界 。
降维则是为了减少模型的复杂性和过拟合的风险。通过减少特征空间的维度,模型可以被迫学习更加精炼和泛化的特征表示。此外,降维可以作为一种正则化手段,有助于提高模型的泛化能力。在某些情况下,降维还可以减少计算成本和提高模型的运行效率 。
在实际应用中,升维后再降维的策略可以被视为一种特征提取和变换的过程。在这个过程中,模型首先通过增加维度来探索数据的内在结构,然后通过降维来提取最有用的特征和模式。这种方法可以帮助模型在保持足够复杂性的同时,避免过度拟合训练数据 。
步骤3:这个特征通过Transformer block进行处理,首先由Attention layer处理,然后是FFN layer。Attention layer横向跨特征处理,而FFN layer则纵向跨维度处理。
步骤4:步骤3为Transformer block的32层重复。最终,结果矩阵的维度与用于特征维度的维度相同。
步骤5:最后,这个矩阵被转换回原始的词汇矩阵大小,即128K,以便模型可以选择并映射词汇中可用的单词。
这就是LlaMa 3在那些基准测试中取得高分并创造LlaMa 3效应的方式。
我们将容易搞混的几个术语用简短的语言总结一下:
1. max_seq_len (最大序列长度)
这是模型在单次处理时能够接受的最大token数。
在LlaMa 3-8B模型中,这个参数设定为8,000个tokens,即Context Window Size = 8K。这意味着模型在单次处理时可以考虑的最大token数量为8,000。这对于理解长文本或保持长期对话上下文非常关键。
2. Vocabulary-size (词汇量)
这是模型能识别的所有不同token的数量。这包括所有可能的单词、标点符号和特殊字符。模型的词汇量是128,000,表示为Vocabulary-size = 128K。这意味着模型能够识别和处理128,000种不同的tokens,这些tokens包括各种单词、标点符号和特殊字符。
3. Attention Layers (注意力层)
Transformer模型中的一个主要组件。它主要负责通过学习输入数据中哪些部分最重要(即“注意”哪些token)来处理输入数据。一个模型可能有多个这样的层,每层都试图从不同的角度理解输入数据。
LlaMa 3-8B模型包含32个处理层,即Number of Layers = 32。这些层包括多个Attention Layers及其他类型的网络层,每层都从不同角度处理和理解输入数据。
4. transformer block
包含多个不同层的模块,通常至少包括一个Attention Layer和一个Feed-Forward Network(前馈网络)。一个模型可以有多个transformer block,这些block顺序连接,每个block的输出都是下一个block的输入。也可以称transformer block为decoder layer。
在Transformer模型的语境中,通常我们说模型有“32层”,这可以等同于说模型有“32个Transformer blocks”。每个Transformer block通常包含一个自注意力层和一个前馈神经网络层,这两个子层共同构成了一个完整的处理单元或“层”。
因此,当我们说模型有32个Transformer blocks时,实际上是在描述这个模型由32个这样的处理单元组成,每个单元都有能力进行数据的自注意力处理和前馈网络处理。这种表述方式强调了模型的层级结构和其在每个层级上的处理能力。
总结来说,”32层”和”32个Transformer blocks”在描述Transformer模型结构时基本是同义的,都指模型包含32次独立的数据处理周期,每个周期都包括自注意力和前馈网络操作。
5. Feature-dimension (特征维度)
这是输入token在模型中表示为向量时,每个向量的维度。
每个token在模型中被转换成一个含4096个特征的向量,即Feature-dimension = 4096。这个高维度使得模型能够捕捉更丰富的语义信息和上下文关系。
6. Attention-Heads (注意力头)
在每个Attention Layer中,可以有多个Attention-Heads,每个head独立地从不同的视角分析输入数据。
每个Attention Layer包含32个独立的Attention Heads,即Number of Attention Heads = 32。这些heads分别从不同的方面分析输入数据,共同提供更全面的数据解析能力。
7. Hidden Dimensions (隐藏维度)
这通常指的是在Feed-Forward Network中的层的宽度,即每层的神经元数量。通常,Hidden Dimensions会大于Feature-dimension,这允许模型在内部创建更丰富的数据表示。
在Feed-Forward Networks中,隐藏层的维度为5325,即Hidden Dimensions = 5325。这比特征维度大,允许模型在内部层之间进行更深层次的特征转换和学习。
关系和数值:
Attention Layers 和 Attention-Heads 的关系:每个Attention Layer可以包含多个Attention-Heads。
数值关系:一个模型可能有多个transformer blocks,每个block包含一个Attention Layer和一个或多个其他层。每个Attention Layer可能有多个Attention-Heads。这样,整个模型就在不同层和heads中进行复杂的数据处理。
下载Llama3模型的官方链接脚本:https://llama.meta.com/llama-downloads/
二、查看模型
下面这段代码展示了如何使用tiktoken库来加载和使用一个基于Byte Pair Encoding (BPE) 的分词器。这个分词器是为了处理文本数据,特别是在自然语言处理和机器学习模型中使用。
我们输入hello world,看分词器如何进行分词。
from pathlib import Path
import tiktoken
from tiktoken.load import load_tiktoken_bpe
import torch
import json
import matplotlib.pyplot as plt
tokenizer_path = "Meta-Llama-3-8B/tokenizer.model"
special_tokens = [
"<|begin_of_text|>",
"<|end_of_text|>",
"<|reserved_special_token_0|>",
"<|reserved_special_token_1|>",
"<|reserved_special_token_2|>",
"<|reserved_special_token_3|>",
"<|start_header_id|>",
"<|end_header_id|>",
"<|reserved_special_token_4|>",
"<|eot_id|>", # end of turn
] + [f"<|reserved_special_token_{i}|>" for i in range(5, 256 - 5)]
mergeable_ranks = load_tiktoken_bpe(tokenizer_path)
tokenizer = tiktoken.Encoding(
name=Path(tokenizer_path).name,
pat_str=r"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+",
mergeable_ranks=mergeable_ranks,
special_tokens={token: len(mergeable_ranks) + i for i, token in enumerate(special_tokens)},
)
tokenizer.decode(tokenizer.encode("hello world!"))